文章目录
- 梯度
- requires_grad
- torch.no_grad()
- 反向传播及网络的更新
- tensor.detach()
- CPU和GPU
- tensor.item()
- 参考文献
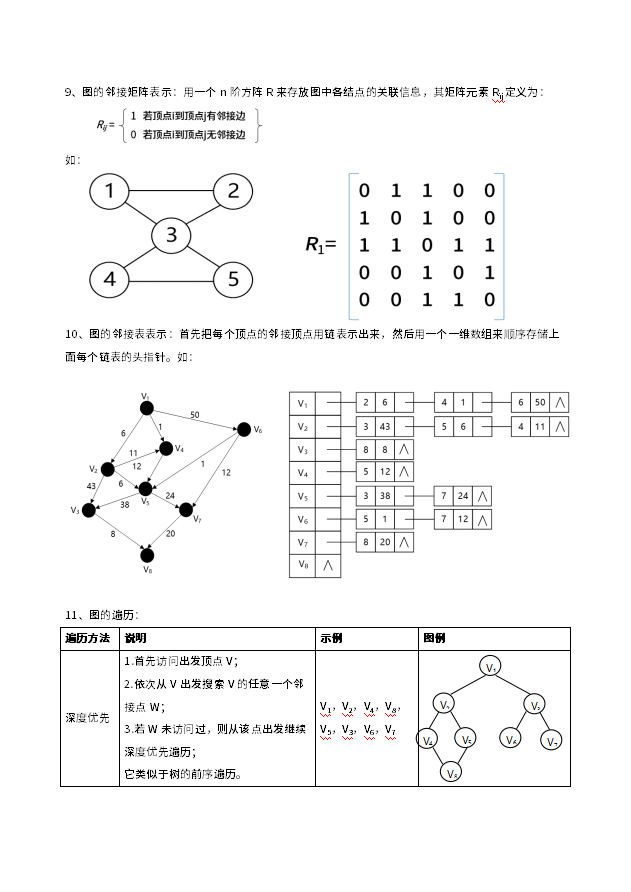
梯度
requires_grad
当我们创建一个张量(tensor)的时候,如果没有特殊指定的话,那么这个张量是默认不需要求导的
我们可以通过tensor.requires_grad来检查一个张量是否需要求导
举一个比较简单的例子,比如我们在训练一个网络的时候,我们从DataLoader中读取出来的一个mini-batch的数据,这些输入默认是不需要求导的;其次,网络的输出我们也没有特意指明需要求导;Ground Truth(Ground Truth指的是为这个测试收集适当的目标数据的过程,即真值)我们也没有特意设置需要求导。这样想下去的话,我们会发现一个问题:为什么神经网络的损失函数Loss可以自动对神经网络的参数进行求导?
虽然输入的训练数据是默认不求导的,但是神经网络中的所有参数,默认是求导的
python">import torch
import torch.nn as nn
# tensor: [batch, channel, width, height]
tensor = torch.randn(8, 3, 50, 100)
net = nn.Sequential(nn.Conv2d(3,16,3,1),
nn.Conv2d(16,32,3,1))
# 0.weight True
# 0.bias True
# 1.weight True
# 1.bias True
for param in net.named_parameters():
print(param[0],param[1].requires_grad)
output = net(tensor)
print(output.requires_grad)
# True
不需要将网络的输入和Ground Truth的requires_grad设置为True,这样做除了增加计算量和占用内存,毫无用处
如果把网络参数的requires_grad设置为False:
python">tensor = torch.randn(8, 3, 50, 100)
print(tensor.requires_grad)
# False
net = nn.Sequential(nn.Conv2d(3, 16, 3, 1),
nn.Conv2d(16, 32, 3, 1))
for param in net.named_parameters():
param[1].requires_grad = False
print(param[0], param[1].requires_grad)
# 0.weight False
# 0.bias False
# 1.weight False
# 1.bias False
output = net(input)
print(output.requires_grad)
# False
通过这种方法,可以在训练的过程中冻结部分网络,让这些层的参数不再更新
torch.no_grad()
当evaluating模型性能时,不需要计算导数,我们可以将这部分的代码放在with torch.no_grad()中,达到暂时不追踪网络参数中的导数
python">x = torch.randn(3, requires_grad = True)
print(x.requires_grad)
# True
print((x ** 2).requires_grad)
# True
with torch.no_grad():
print((x ** 2).requires_grad)
# False
print((x ** 2).requires_grad)
# True
反向传播及网络的更新
定义一个简单的网络,包含两个卷积层、一个全连接层,输出结果的维度是20维
python">import torch
import torch.nn as nn
class Simple(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(3, 16, 3, 1, padding=1, bias=False)
self.conv2 = nn.Conv2d(16, 32, 3, 1, padding=1, bias=False)
self.linear = nn.Linear(32*10*10, 20, bias=False)
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = self.linear(x.view(x.size(0), -1))
return x
# 创建一个很简单的网络:两个卷积层,一个全连接层
model = Simple()
# 为了方便观察数据变化,把所有网络参数都初始化为 0.1
for m in model.parameters():
m.data.fill_(0.1)
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=1.0)
model.train()
# 模拟输入8个 sample,每个的大小是 10x10,
# 值都初始化为1,让每次输出结果都固定,方便观察
images = torch.ones(8, 3, 10, 10)
targets = torch.ones(8, dtype=torch.long)
output = model(images)
print(output.shape)
# torch.Size([8, 20])
loss = criterion(output, targets)
print(model.conv1.weight.grad)
# None
loss.backward()
print(model.conv1.weight.grad[0][0][0])
# tensor([-0.0782, -0.0842, -0.0782])
# 通过一次反向传播,计算出网络参数的导数,
# 因为篇幅原因,我们只观察一小部分结果
print(model.conv1.weight[0][0][0])
# tensor([0.1000, 0.1000, 0.1000], grad_fn=<SelectBackward>)
# 我们知道网络参数的值一开始都初始化为 0.1 的
optimizer.step()
print(model.conv1.weight[0][0][0])
# tensor([0.1782, 0.1842, 0.1782], grad_fn=<SelectBackward>)
# 回想刚才我们设置 learning rate 为 1,这样,
# 更新后的结果,正好是 (原始权重 - 求导结果) !
optimizer.zero_grad()
print(model.conv1.weight.grad[0][0][0])
# tensor([0., 0., 0.])
# 每次更新完权重之后,我们记得要把导数清零啊,
# 不然下次会得到一个和上次计算一起累加的结果。
# 当然,zero_grad() 的位置,可以放到前边去,
# 只要保证在计算导数前,参数的导数是清零的就好。
tensor.detach()
在 0.4.0 版本以前,.data是用来取Variable中的tensor的,但是之后Variable被取消,.data却留了下来
现在我们调用tensor.data,可以得到 tensor的数据 + requires_grad=False,同时tensor和tensor.data共享存储空间,即修改其中一个的值,另一个的值也会发生变化。但是, PyTorch 的自动求导系统不会追踪tensor.data的变化,使用它的话可能会导致求导结果出错
建议使用tensor.detach()来替代tensor.data,tensor.detach()和tensor.data的作用相似,但是tensor.detach()会被自动求导系统追踪,使用起来很安全
python">a = torch.tensor([7., 0, 0], requires_grad=True)
b = a + 2
print(b)
# tensor([9., 2., 2.], grad_fn=<AddBackward0>)
loss = torch.mean(b * b)
b_ = b.detach()
b_.zero_()
print(b)
# tensor([0., 0., 0.], grad_fn=<AddBackward0>)
# 储存空间共享,修改 b_ , b 的值也变了
loss.backward()
# RuntimeError: one of the variables needed for gradient computation has been modified by an inplace operation
在这个例子中,b 是用来计算 loss 的一个变量,我们在计算完 loss 之后,进行反向传播之前,修改 b 的值。这么做会导致相关的导数的计算结果错误,因为我们在计算导数的过程中还会用到 b 的值,但是它已经变了(和正向传播过程中的值不一样了)。在这种情况下,PyTorch 选择报错来提醒我们。但是,如果我们使用tensor.data的时候,结果是这样的:
python">a = torch.tensor([7., 0, 0], requires_grad=True)
b = a + 2
print(b)
# tensor([9., 2., 2.], grad_fn=<AddBackward0>)
loss = torch.mean(b * b)
b_ = b.data
b_.zero_()
print(b)
# tensor([0., 0., 0.], grad_fn=<AddBackward0>)
loss.backward()
print(a.grad)
# tensor([0., 0., 0.])
# 其实正确的结果应该是:
# tensor([6.0000, 1.3333, 1.3333])
这个导数计算的结果明显是错的,但没有任何提醒,之后再 Debug 会非常痛苦
CPU和GPU
tensor.to(device)是 0.4.0 版本之后添加的,当 device 是 GPU 的时候,tensor.cuda()和tensor.to(device)并没有区别
使用tensor.to(device)时,我们可以直接在代码最上面加一句话指定device,后面的代码直接用to(device)就可以了
python">device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
a = torch.rand([3,3]).to(device)
如果我们想把GPU tensor转换成Numpy时,需要先将tensor转换到CPU中,因为 Numpy 是 CPU-only 的;如果 tensor 需要求导的话,还需要加一步 detach,再转成 Numpy
python">x = torch.rand([3,3], device='cuda')
x_ = x.cpu().numpy()
y = torch.rand([3,3], requires_grad=True, device='cuda').
y_ = y.cpu().detach().numpy()
# y_ = y.detach().cpu().numpy() 也可以
tensor.item()
tensor.item()的返回值是一个python数值,不需要考虑此时的tensor数据是在CPU上还是GPU上,但是tensor.item()只适用于tensor包含一个元素的情况
如果想把含多个元素的 tensor 转换成 Python list 的话,要使用tensor.tolist()
python">x = torch.randn(1, requires_grad=True, device='cuda')
print(x)
# tensor([-0.4717], device='cuda:0', requires_grad=True)
y = x.item()
print(y, type(y))
# -0.4717346727848053 <class 'float'>
x = torch.randn([2, 2])
y = x.tolist()
print(y)
# [[-1.3069953918457031, -0.2710231840610504], [-1.26217520236969, 0.5559719800949097]]
参考文献
1、浅谈 PyTorch 中的 tensor 及使用



![[每周一更]-(第121期):模拟面试|微服务架构面试思路解析](https://i-blog.csdnimg.cn/direct/cd3d7a3edfcc41a2b01c6324b8f8d28f.png#pic_center)